Students: Sign up with your .edu email and get $100 OFF instantly!
Master Disaggregated Inference in LLM Serving
Trusted by engineers worldwide
6 Comprehensive Modules
From LLM serving challenges to advanced optimization techniques and production deployment strategies.
Learn at Your Own Pace
Lifetime access to all course materials. Complete sections in order and track your progress along the way.
Certificate of Completion
Earn a professional certificate upon completing all sections to showcase your expertise.
What You'll Learn
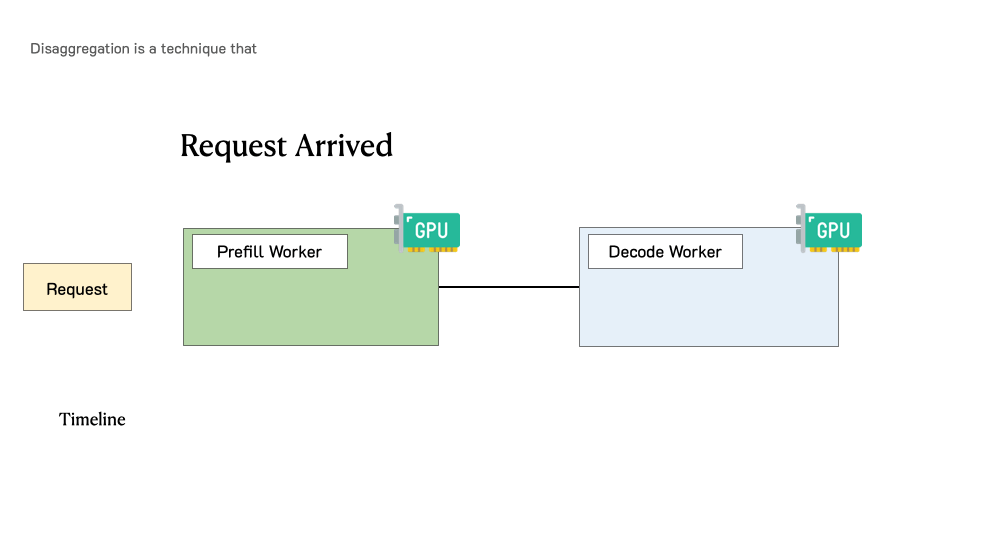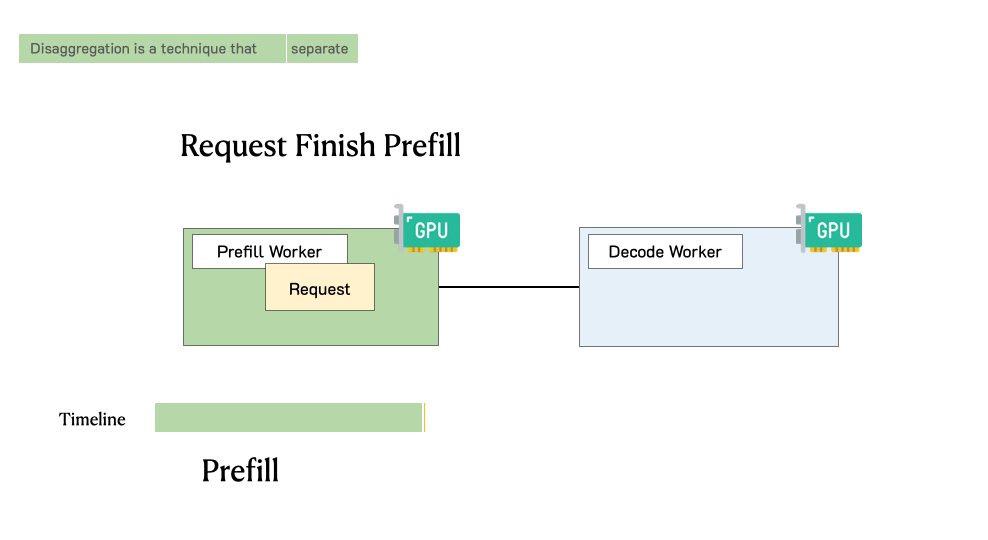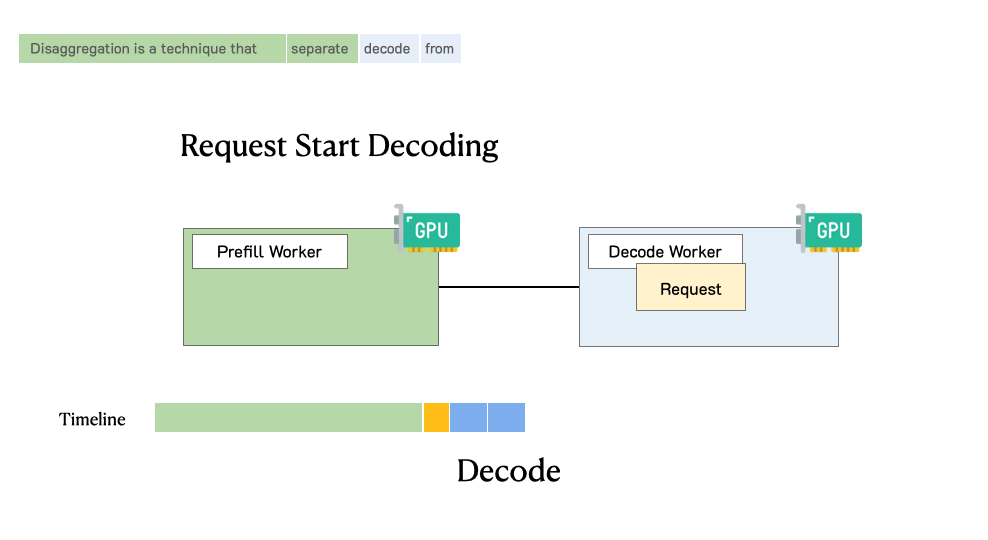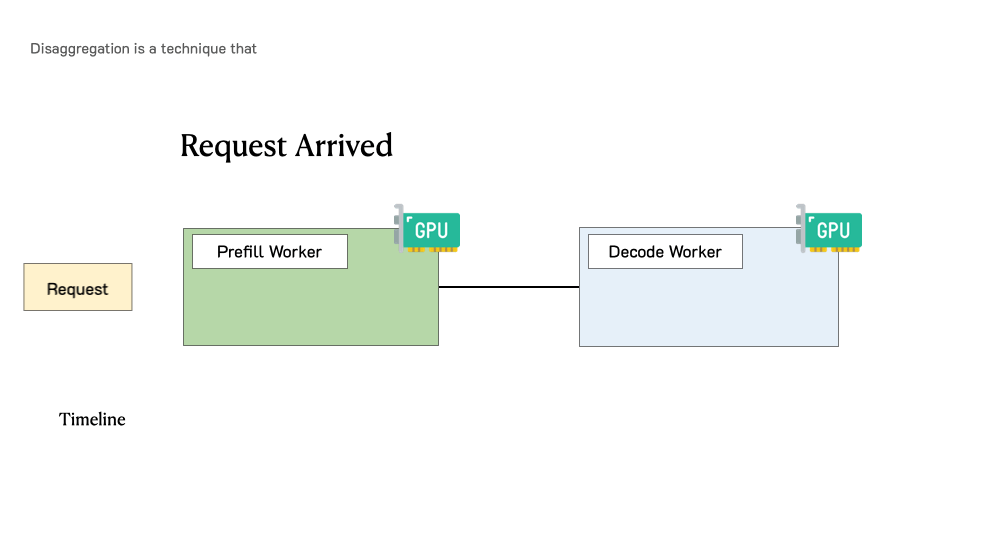
- Understanding LLM serving challenges and bottlenecks
- The two-phase inference process: prefill and decode
- Architecting disaggregated systems for optimal performance
- KV cache management and efficient transfer techniques
- Performance optimization strategies and batching
- Real-world implementation and deployment patterns
- Advanced topics and future research directions
One-time payment
Who This Course Is For
This course is designed for technical professionals who want to master production-grade LLM serving optimization
AI/ML Engineers & Researchers
Building or optimizing LLM inference pipelines
ML Infrastructure / MLOps Engineers
Managing production serving at scale
Data Scientists
Transitioning to systems-level optimization for large models
Startup Founders & Tech Leads
Deploying cost-efficient LLM services (chatbots, agents, APIs)
Students & Professionals
Preparing for roles in frontier AI companies (xAI, OpenAI, Anthropic)
Production Engineers
Scaling inference infrastructure for enterprise applications
Note: This course assumes basic familiarity with LLMs, Python, and inference concepts. Not for absolute beginners.
How This Course Will Accelerate Your Career in AI
Invest in skills that deliver tangible ROI and position you at the forefront of LLM infrastructure
Stand Out in High-Demand Roles
Expertise in disaggregated inference (prefill-decode separation, KV-cache optimization) is rare and increasingly required at top AI labs and inference providers (Fireworks, Groq, Together AI).
Reduce Serving Costs Dramatically
Learn techniques that cut GPU bills 2-5x in production – directly impacting company bottom line and your value as an engineer.
Build Production-Grade Systems
Master real-world patterns used by leading teams (vLLM, SGLang, NVIDIA Dynamo) to handle bursty workloads and scale to thousands of GPUs.
Future-Proof Your Skills
Stay ahead of trends like heterogeneous hardware, Attention-FFN disaggregation, and open-source breakthroughs (DeepSeek, LMCache) – positioning you for 2026-2028 advancements.
Earn a Verifiable Credential
Share your Certificate of Completion on LinkedIn/X/resume to signal deep systems knowledge in the fast-moving LLM space.
Lifetime Access + Updates
Revisit materials as the field evolves (new frameworks, hardware like Rubin/Blackwell impacts). One payment, continuous learning.
What Early Learners Are Saying
Join engineers and researchers already mastering disaggregated inference
"The course explains complex LLM serving concepts in a really clear and structured way. I especially liked how it combines system design ideas with practical exercises. It's a solid resource for engineers who want to understand modern large-scale inference systems."

Chris Harry Patrick
AI/ML Engineer
"This course finally connected the dots between research papers and production serving. The KV-cache transfer deep-dive alone saved our team weeks."
ML Engineer
AI Startup
"Perfect mix of theory and practical deployment patterns. Highly recommend for anyone scaling LLMs in production environments."
MLOps Lead
Tech Company
"Clear explanations of why colocation fails and how disaggregation fixes it. Eye-opening content for systems engineers."
AI Researcher
Research Lab

Why Algorithmic Efficiency Matters More Than Ever
"Most people in the AI community don't yet understand this: the intelligence density potential is vastly greater than what we're currently experiencing. We could extract 100x more intelligence per gigabyte, per watt, per transistor — just from algorithmic improvements alone."
Elon Musk on intelligence density and algorithmic optimization
Frequently Asked Questions
Everything you need to know about the course
Still have questions?
Ready to Master LLM Serving?
Join engineers and researchers worldwide building the next generation of AI infrastructure
Lifetime access • Students pay only $149